Key Takeaways
- In G2’s Spring 2026 reports, Quattr is rated #1 for AI Search Ranking Insights in the Answer Engine Optimization (AEO) category.
- Rank position is no longer a reliable performance metric in AI search; visibility now depends on whether your brand is included, cited, and how it is described within generated answers.
- AI search performance is defined by three independent signals, citations, mentions, and sentiment, which do not move together and cannot be interpreted in isolation.
- Most tools fail because they rely on sampled keywords or API outputs, which do not reflect real, user-facing AI responses.
- Measurement becomes actionable only when these signals are analyzed at the prompt and segment level, revealing whether the gap is authority, coverage, or positioning.
- The teams that win in AI search are not tracking more metrics; they are using accurate, response-level data to make precise decisions on where to build credibility, expand presence, or strengthen positioning.
Enterprise teams have asked the same question for a decade: where do we rank?
It shaped how tools got bought, how reports got built, and how performance got measured. Rank position was consistent, comparable, and easy to tie to a traffic number. Not perfect, but reliable enough to run a campaign around.
AI search broke that reliability.
ChatGPT, Perplexity, Gemini, Claude, and Google AI Overviews don’t return ten blue links in order. They write an answer. And inside that answer, they decide which brands to include, which ones to draw from as sources, and how to describe each one. There is no position one. There is in the answer or not. Cited or just mentioned. Recommended clearly or hedged with a qualifier.
Teams still optimizing for rank position are getting an answer to a question AI search no longer asks.
Google AI Overviews now trigger on 13.14% of global queries (up 72% month-over-month in early 2025), rising to 44.4% overall by late 2025, with 88.1% of informational queries and 8.69% of commercial queries shifting to synthesized answers, no ranked lists.
In Perplexity/ChatGPT, high-authority sites get 40% more citations than mid-tier, while SaaS citation rates average 16% for buyer prompts (leaders hit 74% post-optimization).
As AI systems move from ranking pages to constructing answers, the way visibility shows up and how it needs to be measured changes with it.
The Signals That Actually Matter Now
Yesterday, a higher position meant more visibility. The logic was simple and linear.
Today, that logic doesn’t hold.
The answer is constructed, not ranked. A brand can be completely absent, present but not cited, cited but framed poorly, or cited and recommended directly. Those four outcomes carry very different implications for pipeline and brand perception, and none of them show up in a rank tracker.
What actually tells you how you’re performing in AI search comes down to three things.
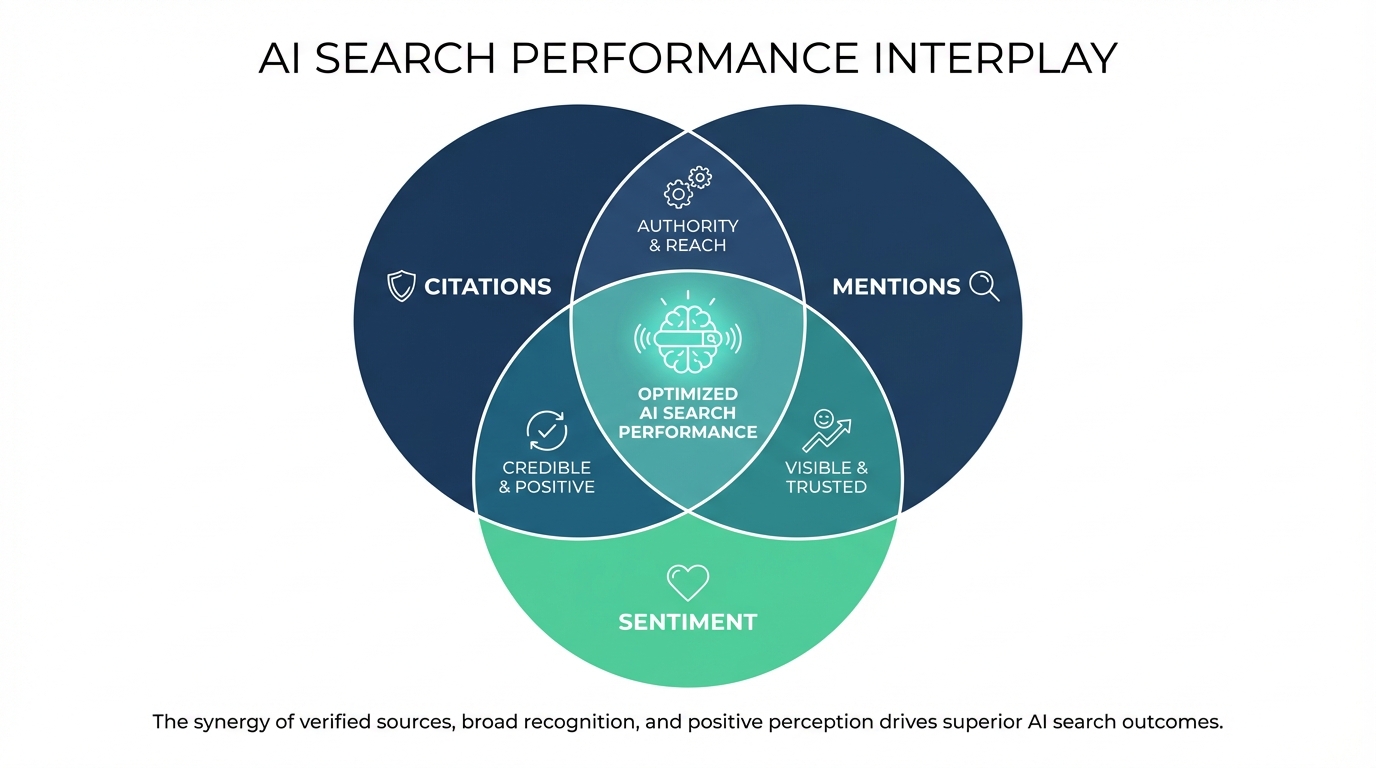
Citations — whether AI systems are pulling from your content to build their answers. This is the strongest signal. If your content is consistently used as a source, you’re influencing what users read, not just appearing somewhere on the page.
Mentions — whether your brand shows up in responses at all, even when it isn’t cited. You can have a meaningful presence in AI answers without being the source. That still matters, but it tells a different story than citation share.
Sentiment — how AI systems actually describe your brand when it does appear. This one catches people off guard. A competitor getting described as the “leading solution” in an AI answer, in a category where your product genuinely outperforms them, is a real business problem. It just doesn’t show up anywhere in a rank report.
These three don’t move in sync. Citation share can grow in one topic area while mention share drops across a broader set of prompts. Sentiment can soften even as overall visibility improves. Looking at any one of them without the others gives you an incomplete read.
Why Most Tools Get This Wrong
Most AI visibility platforms weren’t built from scratch for this problem. They took existing infrastructure, keyword databases, API sampling, and estimated volumes and added mention tracking or sentiment scores on top.
The gap is in the source data. API outputs and keyword samples don’t reflect what a user actually sees when they ask ChatGPT or Perplexity a question. Consumer-facing AI responses shift based on how a prompt is worded, the context of the session, and the system being used. Measurement built on approximations looks thorough until you try to act on it, and the actions end up aimed at the wrong places.
How Quattr Measures It
Quattr pulls responses directly from ChatGPT, Perplexity, Gemini, Claude, and Google AI Overviews, the actual consumer-facing outputs, not API proxies. It tracks citation share, mention share, and sentiment at the prompt level, then groups those prompts into market segments built from first-party data.
That segment layer is what turns the signals from interesting to useful.
A segment where your brand gets mentioned often but rarely cited usually means you have awareness but not credibility in that area. More content isn’t the fix. Deeper, more authoritative content is.
A segment where citation share is strong but limited to a tight cluster of prompts means you’ve built real authority in one place but haven’t extended it to adjacent demand. The opportunity is coverage, not more optimization of what’s already working.
A segment where your brand appears frequently but with flat or neutral sentiment, while a competitor gets warmer framing for a product that isn’t actually better, is a positioning problem. The content exists. It just isn’t saying the right things clearly enough.
Three different patterns, three different responses. A single visibility score or rank position flattens all of that into one number that doesn’t tell you what to do next.
CloudEagle used exactly this kind of segment-level read to identify where citation share was weak and where mentions weren’t building into authority. Optimizing 33 pages over 12 weeks on the back of those insights drove a 3x increase in AI citation share, 113% growth in organic clicks, and shifted 77% of traffic to bottom-funnel queries.
What Changes for the Team
The teams getting real traction in AI search aren’t tracking more signals. They’re asking sharper questions.
Not “what’s our AI visibility score”, but where are we cited versus just mentioned, and how are we being described compared to the competitor we keep losing deals to?
That kind of question needs real response data, organized by segment, across all three signals. Without it, the insight layer looks busy but doesn’t actually tell you where to spend.
Quattr is rated #1 for AI Search Ranking Insights on G2 because it removes that ambiguity. It shows exactly where your brand is being used, where it’s being overlooked, and what needs to change to move from presence to authority.
Quattr Wins Enterprise Trust







Recognized by verified enterprise users on G2.com
If your current reporting can’t explain why competitors are being cited over you, or how your brand is actually positioned inside AI answers, you’re operating without the visibility needed to compete.
See how your brand shows up across ChatGPT, Perplexity, Gemini, Claude, and Google AI Overviews, and where you’re losing influence today. Book a demo to see Quattr in action.

Quattr is an AI-native Search Visibility Platform founded in Palo Alto, California, built for mid-market and enterprise brands competing in the age of generative search. Recently recognized across G2's Spring 2026 reports with #1 rankings in AEO Results, Usability, and Relationship, Quattr helps brands win visibility across traditional search and AI-generated answer surfaces.
Quattr's AI agent, GIGA, evaluates content the way AI systems do, identifying gaps across structure, authority, internal linking, and discoverability to surface the highest-impact fixes. With capabilities like autonomous internal linking, E-E-A-T intelligence, and the new GIGA Landing Page Generator for keyword-matched, AI-search-ready pages, Quattr helps teams move from diagnosis to deployed changes without manual bottlenecks.