Key Takeaways
- AI search isn’t one thing. There’s RAG, query fan-out, semantic chunking, neural reranking, and grounding; each of them is a real lever you can pull, and most blogs treat them as buzzwords. They aren’t.
- The single most important concept to understand is query fan-out. One user question gets expanded into many sub-queries behind the scenes, anywhere from a couple to dozens, depending on the system. You’re no longer optimizing for the question someone typed. You’re optimizing for the invisible questions the model asks on their behalf.
Let me cut to it.
You’ve heard a hundred acronyms in the last twelve months. AEO, GEO, LLMO, AIO. You’ve read posts that promise to explain RAG and end up saying nothing. You’ve been told llms.txt is the future and also that nobody actually uses it. And you’re trying to figure out what’s real, what matters, and what you should actually do on Monday.
This is the post I wish someone had handed me a year ago. We’ll walk through every concept that actually moves the needle in AI search, in plain English, citation datasets, and hands-on implementation work, then translate each one into what it means for your content.
No fluff. No, “the future of search is here.” Just the mechanics, and what to do about them.
The Acronym Mess (Let’s Clear It Up)
Before going anywhere, the vocabulary needs cleaning up. The same ideas are being sold under five different names, and it’s making everyone’s life harder.
- SEO is what you’ve always done. Ranking in Google’s blue links.
- AEO (Answer Engine Optimization) is broader. Optimizing for anything that returns a direct answer, voice assistants, featured snippets, and AI chats.
- GEO (Generative Engine Optimization) is a subset of AEO focused on AI-generated responses. ChatGPT, Perplexity, Claude, Gemini.
- LLMO is the technical guts of GEO. How content gets retrieved, chunked, and cited by language models.
- AIO is narrower still. It’s optimizing specifically for Google’s AI Overviews.
There’s also a newer umbrella term, Search Everywhere Optimization, which captures the reality that “search” now happens across Google, AI chats, Reddit, TikTok, YouTube, and voice. Visibility in one no longer guarantees visibility in the others.
Don’t get attached to the labels. They’ll change. What matters is the machinery underneath them, and that’s what we’ll spend the rest of this post on.
A note on Google’s official guidance
Worth addressing directly. In May 2026, Google published its own guide on optimizing for generative AI features in Search, and on a few points, its framing differs from this post. Be aware of both.
Where Google and this post agree:
- llms.txt isn’t moving the needle. Google has said it has no plans to support llms.txt for AI Overviews ranking, and the citation data backs that up.
- Unique, non-commodity content beats tactics. First-hand perspective, original experience, clear structure, Google, and the citation studies point in the same direction.
- AEO and GEO as categories. Google’s position is that optimizing for AI search is still SEO, because its AI features sit on top of its existing ranking systems. That’s true inside Google. But AEO and GEO describe a broader practice: optimizing for ChatGPT, Perplexity, Claude, and Gemini, which retrieve, chunk, and cite differently from Google. The labels exist because the work is different once you step outside Google’s ecosystem.
- Don’t keyword-stuff or write mechanically for machines. Both agree.
Where the framing differs:
- Chunking. Google says you don’t need to break content into pieces; their systems understand multi-topic pages. True for Google. But this post is about ChatGPT, Perplexity, Claude, and Gemini, too, and those systems do retrieve at the passage level. Writing self-contained paragraphs helps across the board, whether Google specifically asks for it or not.
- Off-site mentions. Google warns against seeking inauthentic mentions. Agreed, inauthentic ones don’t work. But the citation data on ChatGPT and Perplexity (Wikipedia, Reddit, YouTube, third-party publications) shows that authentic off-site presence is a real input to AI visibility, especially outside Google’s ecosystem.
- Structured data. Google says it isn’t required for generative AI search. Also true. But it’s still a cheap way to help models parse and ground claims, and it has a standalone value for rich results regardless.
The honest read: Google’s guidance is correct for Google Search. This post is broader because AI search is broader. If 100% of your AI visibility came from Google AI Overviews, Google’s guidance would be sufficient. It doesn’t, so it isn’t.
Retrieval-Augmented Generation(RAG): The Architecture Behind AI Answer
Almost every AI search experience you’ve used in the last two years runs on RAG, Retrieval-Augmented Generation. If you understand one concept from this post, make it this one.
Here’s how AWS defines it: RAG is a technique for augmenting a large language model with external data, providing the context it needs to produce accurate, useful output.
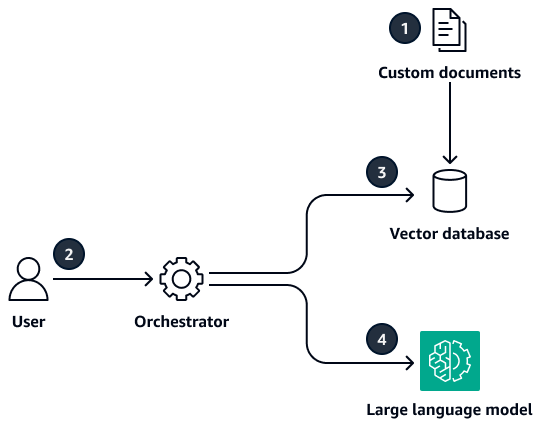
Source: docs.aws.amazon.com
Translated: when you ask ChatGPT or Perplexity a question, the system doesn’t just generate an answer from what it learned during training. It runs a live search, pulls back relevant chunks of content, and uses those chunks to write the answer. The model isn’t your competitor. The model is the interface. Your content is what it’s reaching for in the background.
What this means for your content: you are no longer trying to be the best page. You’re trying to be the best retrievable evidence. That’s a different game. The model doesn’t read your page top-to-bottom. It pulls back paragraphs, evaluates them, and uses the ones it can verify cleanly. If your content isn’t structured in a way that survives being pulled out of context, it loses, no matter how good the page is as a whole.
Query Fan-Out: The Most Important New Concept
This is the one you have to get right.
Here’s how Google describes it in its own documentation on AI Mode: both AI Overviews and AI Mode may use a “query fan-out” technique, issuing multiple related searches across subtopics and data sources, to develop a response.
How many sub-queries? It varies a lot. Industry studies put it anywhere from roughly two searches per query in ChatGPT’s standard search mode (Nectiv found 2.17 on average) to 10–20 sub-queries in some Google AI Mode examples, with extreme cases like ChatGPT Deep Research firing off hundreds. The honest answer is “several, sometimes dozens.” The point isn’t the exact number. The point is that one user question becomes many retrieval queries.
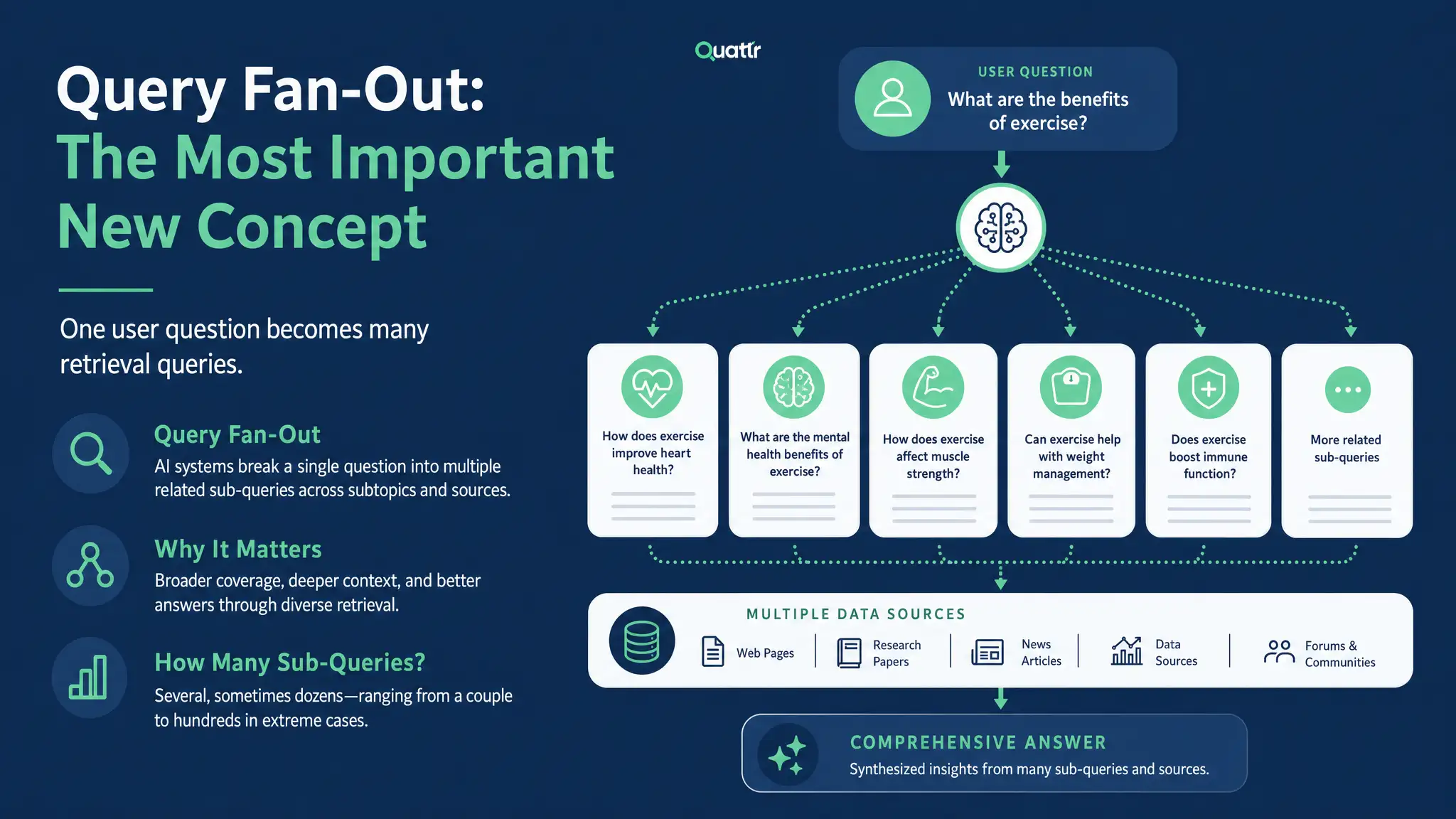
Think about what this actually means. Someone types “best CRM for a small SaaS team” into ChatGPT or Google’s AI Mode. The system doesn’t run that query against an index. It expands it into something like:
- pricing tiers for SaaS-friendly CRMs
- integration ecosystem comparison
- best CRMs for under 50 users
- user reviews of leading SaaS CRMs
- onboarding experience
- scalability concerns at Series A
- which CRMs integrate with Stripe and Slack
- feature comparison: HubSpot vs Salesforce vs Pipedrive
Then it retrieves content for each of those sub-queries, ranks the chunks, and stitches together one answer.
What this means for your content: you are no longer ranking for the question someone typed. You are ranking for the invisible sub-questions the AI generates on their behalf. A page that perfectly answers the literal prompt but misses the fan-out loses to a competitor that covers the underlying components.
The practical consequence is that topical breadth often beats depth on a single facet when retrieval systems fan out across many sub-questions.
That doesn’t eliminate the value of originality or expertise. Breadth helps content get retrieved across more sub-queries; unique insight helps it survive reranking and grounding.
Semantic Chunking: Your Page Isn’t What Gets Retrieved
This is the one that surprises most marketers.
When an AI system retrieves content, it doesn’t grab your whole page. It grabs chunks, semantic units of meaning. Paragraphs, sections, sometimes even single sentences. Each chunk is indexed and ranked independently.
You don’t control which chunking method a given system uses (fixed-size, recursive, or layout-aware are the common ones). But you do control whether your content chunks cleanly.
What this means for your content: every paragraph needs to be self-contained. If a paragraph in your post requires three previous paragraphs to make sense, it’s nearly useless to a retrieval system. The chunks that win are the ones that can be lifted out, dropped into a synthesized answer, and still read as a complete thought.
What helps: write H2s that are real questions. Open each section with the answer. Don’t make pronouns refer back across sections. Don’t assume the reader has read the paragraph above.
Dense Retrieval and Embeddings: Why Keyword Stuffing Is Dead
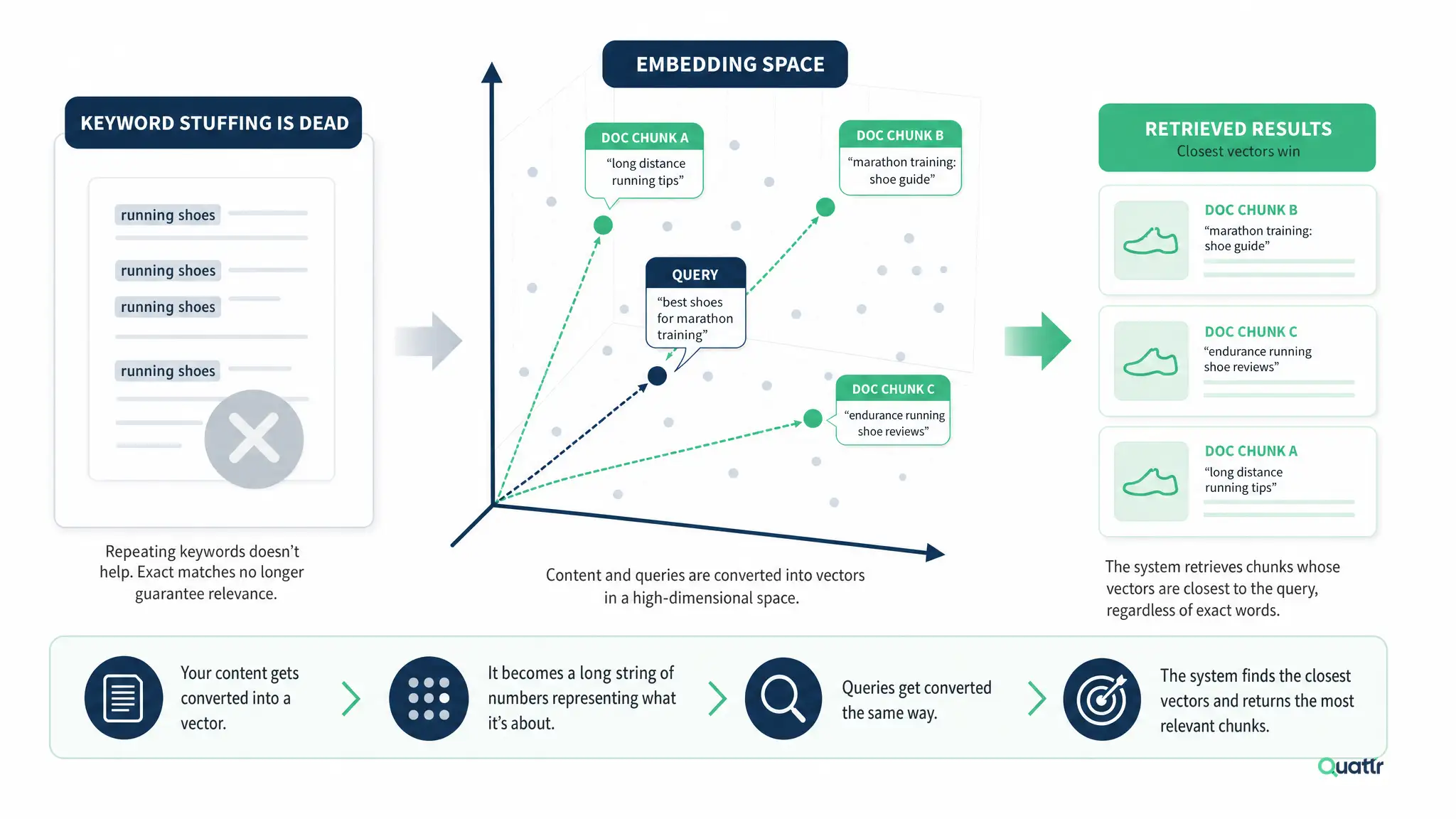
When AI systems search for relevant chunks, they’re not matching keywords. They’re matching meanings.
Your content gets converted into a vector, a long string of numbers representing what it’s about in a high-dimensional space. Queries get converted the same way. The system retrieves chunks whose vectors are closest to the query’s vector, regardless of whether the exact words match.
What this means for your content: a paragraph about “reducing customer churn through onboarding emails” can win for a query about “increasing retention with welcome sequences.” The keywords don’t overlap. The meaning does.
Stop optimizing for exact-match keywords. Optimize for concepts, for the actual question being asked, for the way real humans phrase things. Synonyms, related concepts, examples, and natural language all help. Awkward keyword stuffing actively hurts, because it makes your content read as less semantically coherent.
Neural Reranking: The Head-to-Head Stage
After the initial retrieval pulls back candidate chunks, a second model, the reranker, evaluates them head-to-head against the query and reorders them by relevance and quality.
This is where chunks that seem relevant by keyword often lose to chunks that are actually more informative or better phrased.
What this means for your content: answer-first writing crushes here. A chunk that opens with the answer scores higher in head-to-head evaluation than one that opens with context and gets to the point in paragraph four. The reranker is looking at the first sentence or two of each chunk to decide whether to promote it. Bury the lede, and you lose.
Passage-Level Indexing: Why a Small Site Can Beat a Big One
Here’s the great equalizer.
Because the system retrieves and ranks chunks, not pages, a single paragraph from a 500-word post on a small blog can outrank a 5,000-word ultimate guide from a major publication, if that paragraph is a sharper match for a specific sub-query.
That’s how passage-level retrieval systems are designed to work, though domain authority and broader trust signals still influence which passages ultimately get surfaced.
What this means for your content: you don’t need to write the longest, most comprehensive piece on a topic. You need to write the cleanest, most extractable piece on each sub-aspect of a topic. The asset is no longer the page. It’s the passage.
Stop measuring success by word count. Start measuring it by how many of your individual paragraphs could stand alone as the answer to a specific question.
Grounding: The Anti-Hallucination Layer
This is the safety system that decides whether your content gets used at all.
AWS describes grounding as the process that grounds foundation model responses in external, domain-specific knowledge, delivering both factual accuracy and contextual relevance. In plain English: the model is terrified of saying something wrong. So it leans hard on sources it can verify.
What this means for your content: pages that are easy to ground get cited. Pages that are hard to ground get skipped. Easy-to-ground means:
- Clear publication date
- Named author with credentials
- Citations to authoritative sources within the content
- Schema markup (Article, Author, Organization)
- Factual claims phrased as factual claims, not opinions
If a model can’t tell who wrote your content, when it was written, or whether it’s been verified against other sources, it will move on to a page where it can.
How to Actually Write for Retrieval
Five rules. Internalize these, and most of the rest follows.
1. Lead with the answer. Inverted-pyramid journalism is now the optimal structure for AI retrieval. The first sentence of every section should be capable of standing alone as the answer to a question. Context, nuance, and evidence go underneath.
2. Make every paragraph chunk-worthy. If a paragraph can’t be lifted out and still make sense, rewrite it.
3. Cover the topic completely. Definitions, mechanics, comparisons, common objections, edge cases, examples. The fan-out is going to probe all of these. Cover all of them on the same page or across a tight cluster of pages.
4. Add information gain. Original research, first-party data, expert quotes, your own statistics, and real case studies. The model has read every generic recap of the topic. It hasn’t read your data.
5. Stay fresh. AI engines actively prefer recent content. An Ahrefs analysis of 17 million AI citations across 7 platforms (July 2025) found that AI-cited content is 25.7% fresher on average than what ranks in traditional Google organic results. Add visible “last updated” dates. Refresh stats. Republish evergreen pieces with new examples.
Authority Has Changed More Than Anything Else
This is where intuitions from classical SEO break the most.
Brand Mentions vs. Citations: The Dual Signal
A citation is when the model links your URL as a source. A mention is when the model writes your brand name in the answer text. These are not the same.
The most durable form of AI visibility is both at once. Semrush found that brands are mentioned in 26% to 39% of AI responses across five LLMs, which shows how often brand visibility shows up inside the answer itself, not just as a linked source.
Off-Site Presence Has Quietly Become More Important Than On-Site
This is the uncomfortable part.
AI systems do not draw from the same sources, and the mix changes fast enough that no single percentage should be treated as permanent truth. In one study, ChatGPT’s citations were dominated by Wikipedia, which accounted for nearly half of its top-10 cited sources, while Google AI Overviews leaned more toward Reddit and YouTube, and Perplexity showed especially heavy Reddit concentration.
That matters because AI visibility is increasingly shaped by where your brand shows up across the web, not just what is published on your own site. Community discussions, reference pages, and platform-native content can all influence whether your brand appears in an answer, even when your site itself is not the primary source.
Look at the pattern, not the exact numbers. If you’re not present on Wikipedia, Reddit, YouTube, and major third-party publications, you’re invisible across huge swaths of AI search, regardless of how good your own site is. Brand authority is now distributed across the open web. Your domain is one input among many.
What this means for your content: your content strategy has to include earning mentions on the platforms that AI engines actually read. Get a real Wikipedia presence (this is hard; it requires genuine notability). Be active where your audience already is on Reddit. Publish to YouTube. Get cited in industry publications. Stop treating off-site as a “PR thing”; it’s now a core retrieval signal.
Co-Citation
When authoritative sources mention your brand alongside other authoritative sources, the model learns to associate you with that peer group. A mention in a Wikipedia article that also references industry leaders does more for your AI visibility than ten high-DA backlinks to your homepage. Co-citation is the new link building.
E-E-A-T, Evolved
Experience, Expertise, Authoritativeness, Trust. Still matters. But now it’s interpreted through AI-readable signals: named authors with verifiable credentials, structured author schemas, organizational affiliations, citations to and from authoritative bodies, and consistent entity representation across the web.
The Technical Needs
Three areas. Get them right.
AI Crawler Access
A growing fleet of bots needs explicit access to your content. GPTBot. OAI-SearchBot. ClaudeBot. PerplexityBot. Google-Extended. Many sites have inadvertently blocked these crawlers via aggressive Cloudflare bot rules, blanket robots.txt directives, or WAF configurations.
Audit your bot access policies today. Allowing AI crawlers is a deliberate choice. Blocking them by accident is a tragedy.
Server-Side Rendering
If your content only materializes after JavaScript runs in a browser, many AI crawlers won’t see it. SSR or static generation for any content you want retrieved is now table stakes. If your site is a Next.js or Nuxt app, make sure pages are rendered server-side.
Schema Markup
Article, Organization, Author, Product, and Review schema remain useful because they help search engines and AI systems understand entities, relationships, and claims on the page. FAQ and HowTo schema are still valid structured data formats, but Google no longer surfaces FAQ rich results broadly and has scaled back HowTo rich result support. Their value today is less about SERP features and more about helping machines interpret content.
The llms.txt Question
A file called llms.txt, modeled on robots.txt, has been proposed as a way to tell LLMs what to read on your site. Let me be honest about this one.
A study analyzed roughly 300,000 domains in November 2025 and found no correlation between having a llms.txt file and AI citation frequency. Adoption sits around 10% of domains.
Translation: it’s not moving citations today. Should you implement it? Maybe. It’s cheap insurance for the agentic web that’s coming. But treat it as “watch this space,” not as a current lever. Anyone telling you llms.txt is the biggest win in AEO right now is selling you something.
Measurement: You Can’t Optimize What You Can’t See
Rank tracking is largely useless here. AI answers don’t have stable rank positions. They have appearances, which vary by phrasing, model, user context, and time of day. The new measurement stack has three pieces.
Share of voice across platforms. Track how often your brand is cited and mentioned across ChatGPT, Perplexity, Google AI Overviews, Claude, and Gemini for your priority queries. Both citation share and mention share matter; they’re different signals.
Provider gap analysis. Identify where you appear strongly on one platform but weakly on another. A brand might be a Perplexity favorite while being invisible on ChatGPT because ChatGPT leans on Wikipedia, and you have no Wikipedia presence. Each gap suggests a different fix.
Multi-platform tracking by default. No single AI platform is dominant enough to track in isolation. If your tooling only covers one, you’re flying blind.
What’s Coming Next
A few concepts worth getting ahead of.
Multimodal optimization. Models increasingly process text, image, video, and audio together. Brands with consistent presence across formats, video transcripts, image alt text, podcast descriptions, and structured visual content- show up in AI answers more reliably than text-only competitors, though the magnitude of the lift varies a lot by category and study. Multimodal is now part of the AEO surface area.
Entity SEO and knowledge graph alignment. Models reason in entities, not strings. Making sure your brand, products, people, and concepts are represented consistently across Wikipedia, Wikidata, schema, and third-party sources is becoming foundational. Entity ambiguity, multiple companies with similar names, inconsistent founder attributions, and conflicting product descriptions degrade AI visibility more than any keyword issue ever did.
The agentic web and B2A (Business-to-Agent). The next interface isn’t the chat box. It’s the autonomous agent acting on a user’s behalf, booking flights, comparing vendors, and filing expenses. Designing for agent consumption (clean APIs, structured data, machine-readable pricing, and eventually llms.txt) is where the next round of optimization happens. It’s early. It will not stay early for long.
Personalization in AI answers. AI systems are quietly personalizing responses based on user context, history, and inferred intent. The same query from two users will increasingly return different answers and different citations. Average visibility is becoming less meaningful than segment-specific visibility.
The Simplest Thing You Can Do This Week
Pick one page on your site that should be getting cited and isn’t. Your best explainer. Your most-visited comparison page. Your highest-intent FAQ.
Open it. Then read it the way an AI engine would read it.
Ask yourself:
- If the system landed here looking for a clean answer to one specific question, what does it find in the first two sentences of each section?
- Are the H2s questions a real human would type?
- Is every paragraph self-contained, or do they depend on context from elsewhere on the page?
- Is the publication date visible? When was it last updated?
- Are the stats more than 12 months old?
- Are there named authors with credentials?
- Does the page cover all the sub-topics the fan-out is likely to probe?
- One more thing: search your brand in ChatGPT, Perplexity, and Google AI Overviews. Note which third-party sources appear repeatedly. Those sources are often more important to your AI visibility than another blog post on your own domain.
If you answered “no” to half of those, that’s your project for the week. The rewrite isn’t huge. But the difference between a page that gets cited and one that gets skipped often comes down to twelve sentences and a clean structure.
One Thread Running Through All of This
Most posts on AEO hand you a glossary and let you assemble it yourself. The thread that ties everything in this post together is the pipeline AI search actually runs:
A user query → fans out into many sub-queries → which retrieve chunks via dense semantic search → which get reranked head-to-head → which get grounded into a synthesized answer → which cites some sources and mentions some brands → which over time reinforces which brands the model associates with which topics → which feeds back into future retrieval.
Every concept in this post is a leverage point on that pipeline. Query fan-out tells you to cover topics broadly. Chunking tells you to structure cleanly. Dense retrieval tells you to write for meaning. Reranking rewards answer-first writing. Grounding rewards machine-readable signals. The mention-citation dynamic explains why off-site presence is now core, not peripheral.
The teams that win at AEO in the next 12 months won’t be the ones with the longest checklist. They’ll be the ones who internalized the pipeline and made every content, technical, and PR decision to feed it.
FAQs on AI Search and AEO
AEO (Answer Engine Optimization) is the broad discipline of optimizing for any answer engine, including voice and featured snippets. GEO (Generative Engine Optimization) is a subset focused on AI-generated responses from ChatGPT, Perplexity, Claude, and Gemini. LLMO is the technical layer of GEO, how content is retrieved, chunked, and cited by language models. In practice, most teams use AEO and GEO interchangeably.
Yes, but unevenly. Google AI Overviews sits on top of Google’s existing ranking systems, so SEO foundations carry over. Perplexity leans heavily on Bing, so being indexed there matters. ChatGPT relies more on training data and Wikipedia. The honest answer: SEO is necessary but no longer sufficient. Your content needs to be discoverable and retrievable and citable.
Query fan-out is when an AI system breaks a single user query into multiple sub-queries, anywhere from a couple to dozens depending on the platform and query type — retrieves content for each, and synthesizes the results into one answer. It matters because you’re no longer optimizing for the question someone typed. You’re optimizing for the invisible sub-questions the model generates on their behalf. Topical breadth becomes more important than depth on any single facet.
ChatGPT pulls heavily from Wikipedia and high-authority third-party sources in its training data, plus live retrieval when browsing is enabled. Getting cited means earning presence on the sources ChatGPT trusts, Wikipedia (which requires genuine notability), authoritative industry publications, and well-structured content on your own domain that’s been around long enough to appear in training corpora.

Quattr is an AI-native Search Visibility Platform founded in Palo Alto, California, built for mid-market and enterprise brands competing in the age of generative search. Recently recognized across G2's Spring 2026 reports with #1 rankings in AEO Results, Usability, and Relationship, Quattr helps brands win visibility across traditional search and AI-generated answer surfaces.
Quattr's AI agent, GIGA, evaluates content the way AI systems do, identifying gaps across structure, authority, internal linking, and discoverability to surface the highest-impact fixes. With capabilities like autonomous internal linking, E-E-A-T intelligence, and the new GIGA Landing Page Generator for keyword-matched, AI-search-ready pages, Quattr helps teams move from diagnosis to deployed changes without manual bottlenecks.