Quattr Leads AEO, SEO, and Content Rankings on G2 Spring 2026.
Quattr Leads AEO, SEO, and Content Rankings on G2 Spring 2026.

As a website owner, you may have experienced the frustration of suddenly seeing your website traffic drop off. This could be due to the Googlebot crawler being unable to access your site. However, Googlebot is not your enemy; rather, it is a friend that can help you optimize site visibility and ensure consistent traffic.
Google bots are more of a gateway to unlocking your site's full potential.
Without its favorable glance, your content could languish in obscurity, buried under the mountain of information on the internet. It may lead to decreased visibility on search engine result pages.
In this blog, we will delve deeper into the world of Googlebot crawling & how you can optimize your website to ensure it is crawled effectively. So, without further ado, let's dive into the world of Googlebot crawling!
9.
10.
A web crawler, sometimes called a bot or spider, is a program that automatically visits websites and reads their pages. It moves from one page to another by following links, collecting information along the way.
Search engines like Google use crawlers (such as Googlebot) to find new pages, update existing ones, and understand how websites are connected. This helps them store information and show relevant results quickly when someone searches online.
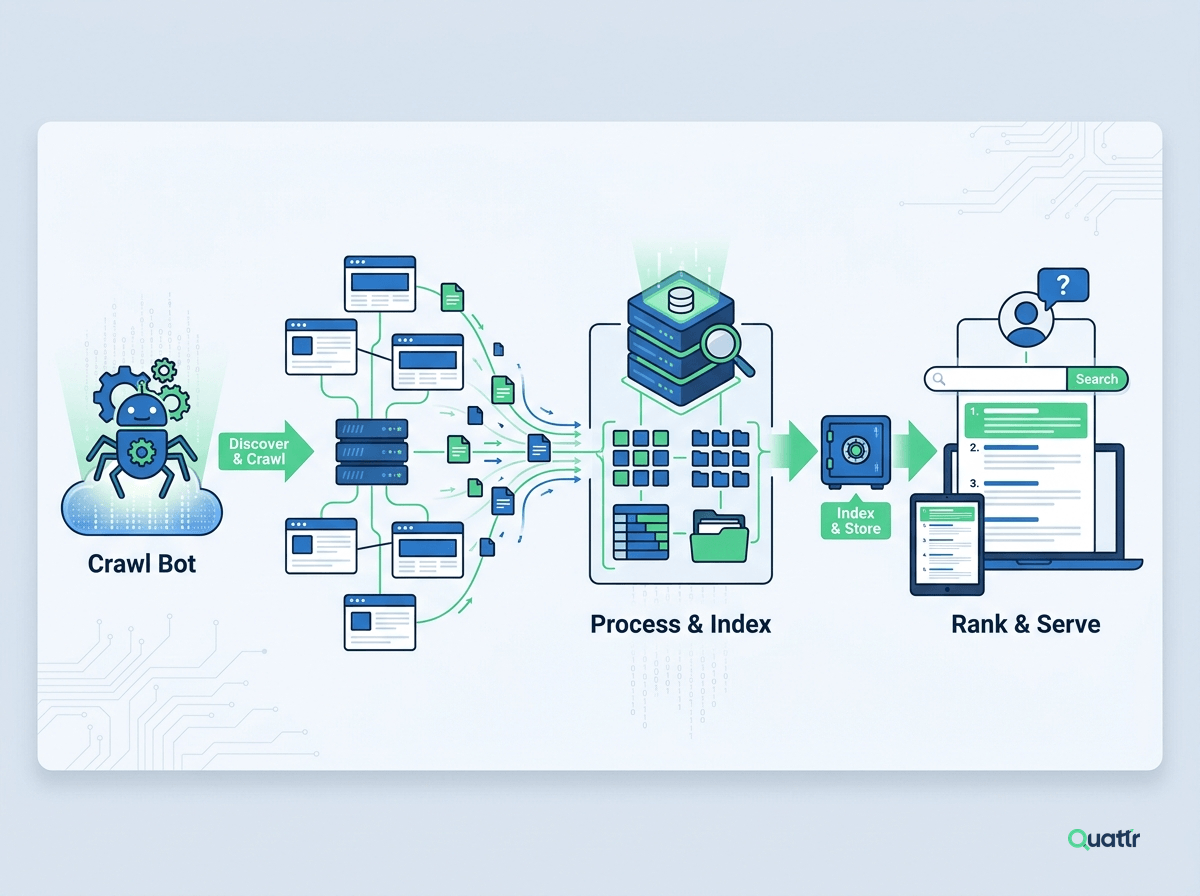
A web crawler, such as Googlebot, acts like an eager reader exploring a vast library of online 'books' or websites. At its heart, it operates with three key components: the frontier, the fetcher, and the scheduler.
The frontier is the list of URLs queued for a visit, akin to a reader's wishlist. The fetcher grabs the web page's content, much like reading a book, while the scheduler decides which 'book' to read next based on priority & organization.
Googlebot begins its reading journey by visiting a few 'libraries' (servers with websites). It starts with familiar 'books' (known websites) and then uses the links within these 'books' as a roadmap to discover new 'books' (new websites or pages).
However, it can encounter 'locked doors' like broken links or access errors, which it skillfully bypasses, ensuring only accessible & valid pages are added to its collection. This efficient system allows Googlebot to sift through seamlessly & index the ever-changing web landscape.
Several factors could be at play if you've noticed that Googlebot isn't crawling your website:
1. Check Your Robots.txt: Ensure your robots.txt file isn't blocking Googlebot. It is crucial to how the Google crawler interacts with your site. If your robots.txt file accidentally tells Googlebot not to crawl your website, it will heed that instruction.
2. Low-Quality or Duplicate Content: Googlebot aims to index high-quality & unique content. It may reduce the crawl rate or even stop crawling your site altogether if it encounters too many pages with similar or poor content.
3. Server Problems: If your server is slow or often down when the Googlebot tries to visit, it can decrease your site's crawl frequency. Googlebot doesn't want to cause additional load on your server & may limit its visits if it encounters server errors or slow response times.
4. Lack of Backlinks: Googlebot might not crawl your website if it is new & has few backlinks. Backlinks are vital for Googlebot to discover new websites. If your website lacks quality backlinks, Googlebot might take more time to crawl and index it. So, it's crucial to develop a strong link-building strategy.
5. High Page Load Time: Googlebot allocates a specific crawl budget to each website, meaning it has limited time to crawl & index pages. If your site loads slowly, Googlebot may leave before it has crawled all pages.
Understanding and rectifying these issues will help Googlebot crawl and index your site efficiently. Learn how to identify & fix crawling errors in Google Search Console.
After crawling a website, Google starts indexing. Indexing is when Google sorts & organizes the site's content so people can find it easily in search results. Googlebot looks at things like text, images, and videos to understand what the website is about.
It then puts this information into Google's big database. The better a website talks to Googlebot - using the right keywords, updating regularly, and being easy to use - the higher it will likely appear in search results. Google uses special formulas to decide which websites show up first. It look at how relevant the information is, its structure, how the website is built, and user experience.
But remember, not every page that Googlebot visits gets stored in Google's database. Sometimes, there are issues, and a webpage might not be indexed. These errors occur due to numerous factors:
1. The webpage is disallowed in your robot.txt file.
2. The webpage has a "noindex" meta tag.
3. The webpage is blocked by a password.
4. The webpage is unreachable or presents a 404 error.
5. The webpage is a duplicate of other pages and doesn’t provide any unique value.
6. The webpage is significantly under-optimized in terms of SEO.
Learn how to rectify indexation errors in GSC here.
Google crawling and Google indexing are two essential processes in the search engine ecosystem, both crucial for effective website visibility. While they are interconnected, they serve distinct purposes in optimizing search results. Let us learn how they are different.
Google uses various types of crawlers to collect data from the web, including text, images, videos, and audio. These crawlers have different functions & are specialized in different types of content.
Googlebot Smartphone is a specialized crawler designed to index web pages optimized for mobile devices. It emulates smartphone user agents & makes mobile-optimized pages available for mobile users. This crawler helps ensure your website is accessible & functional for mobile users.
The user token here is "Googlebot Smartphone" and the full agent user string would look something like "Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)."
Contrary to its mobile counterpart, Googlebot Desktop emulates a traditional desktop-user agent. This crawler specializes in analyzing & indexing web pages optimized for larger screens.
Its user token is "Googlebot" and a typical full agent user string might come off as "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)." This crawler is beneficial in ensuring your website is accessible & functional for desktop users.
Googlebot Image specializes in discovering & indexing images available on the web. It's designed to help Google's image search functionality.
The user token associated with it is "Googlebot-Image" and the full agent user string usually appears as "Googlebot-Image/1.0." The benefit of this bot is that it can help your images appear in Google Images, leading to increased visibility & potentially more web traffic.
Googlebot Video is deployed to crawl, index, and rank video content on the web for Google Video search. Its user token is "Googlebot-Video" and the full agent user string is "Googlebot-Video/1.0". It increases the visibility of your website on Google's video search, leading to more viewers & higher engagement rates.
Google AdsBot is a crawler designed to crawl & index web pages containing Google AdWords advertisements. It is responsible for analyzing the content of each AdWords advertisement and determining its relevance & quality.
The user agent for the desktop version of this bot is 'AdsBot-Google (+http://www.google.com/adsbot.html),' and there's a mobile version, too, identified by 'AdsBot-Google-Mobile.'
Google bots are essential for indexing web content, helping Google's search engine find relevant information quickly. However, it's crucial to be aware that not all bots claiming to be Google are legitimate. Some may pose as Google bots to scrape & steal website content or bypass security measures. Google advises website owners to verify the authenticity of bots crawling their sites.
To ensure a bot is a genuine Googlebot, Google provides a list of IP addresses associated with its crawlers. But there's also another way to check the activity of Google bots on your site. Google Search Console (GSC) provides a comprehensive report related to crawl stats. This report can be utilized to monitor Googlebot activity, allowing you to identify any unusual or suspicious actions. Follow the steps to check the Googlebot activity:
1. Log in to GSC and select your website.
2. Navigate to "Settings" and then "Crawl Stats" to access detailed reports on Googlebot interactions.
3. Look for data like 'Host status,' 'Crawl requests,' and other crawl stats.
An unusual spike in crawl requests could indicate suspicious bot activity.
The robots.txt file is a simple text file that sits at the root directory of your website & instructs Googlebot which pages of your website to crawl & index. You can use this file to block specific pages or entire sections of your website from being crawled. To create a robots.txt file, you need to follow specific directives. The most common directives include "User-agent", "Disallow", and "Allow".
Learn more about the Robots.txt file & how to implement them here.
Unlike Robots.txt, which is a standalone file, the Meta Robots Tag is an HTML tag placed in the header section of a webpage. This tag instructs crawlers whether or not to index a particular page & follow its links.
With attributes like "index"/"noindex" and "follow"/"nofollow," it lets you fine-tune the indexing & link-following behavior of specific pages. This tag is useful to prevent duplicate content issues or exclude specific pages from being indexed. It is also useful when you don't want to pass link equity to external pages.
The choice to use "noindex" and "nofollow" depends on the specific requirements of your website. For instance, you could use "noindex" for duplicate pages and pages with sensitive information and "nofollow" for links to untrusted content or paid links.
URL parameters are used to track specific campaign data, sort information, or produce dynamic content. They are used to pass additional information to a web page. However, if not handled carefully, they can cause significant SEO problems by creating duplicate content issues.
Maintaining a clean URL structure & minimizing unnecessary parameters helps ensure Googlebot's efforts are focused and effective, avoiding potential crawl issues.
The crawl rate determines how often Googlebot visits your site. While Google automatically determines the optimal crawl rate, you can adjust this rate in Google Search Console under 'Settings.'
It should be noted that a higher crawl rate does not necessarily lead to higher rankings, and an excessive crawl rate might put unnecessary load on your server. Therefore, it's best to trust Google's judgment unless you experience server load issues or your site content changes rapidly.
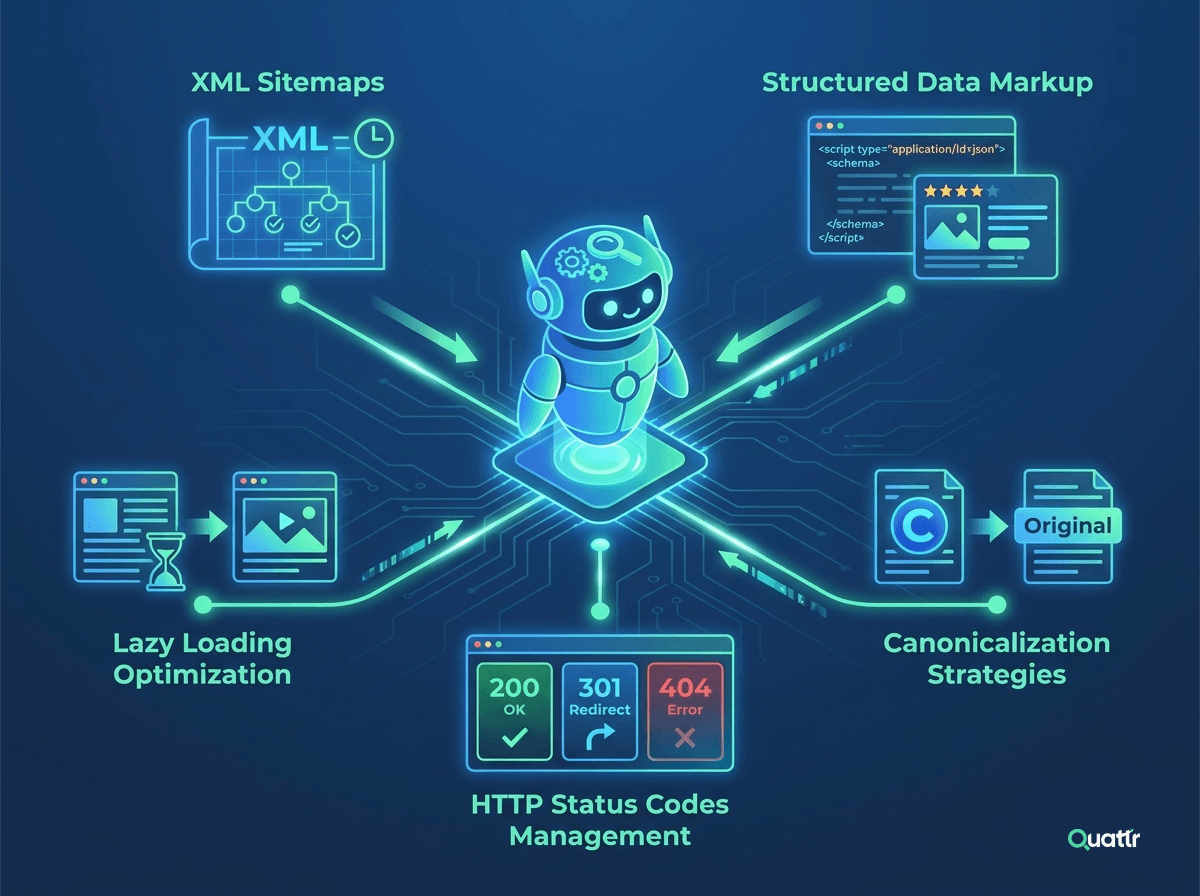
XML Sitemaps are files that tell Google & other search engines about the pages available on your website. They provide crucial information such as the last update, frequency of changes, and the importance of pages in relation to other pages on the website.
These XML sitemaps can be generated using numerous free & paid online tools. Once the sitemap is generated, it should be submitted to Google Search Console and added to your site's robots.txt file.
It significantly enhances Googlebot's crawling efficiency and helps search engines discover & index your content faster, improving organic visibility.
Structured Data Markup is code that helps search engines understand your content better. It’s a way to label or annotate your content so that search engines can index it more effectively.
Use Google’s tools to mark up your site's content, validate it, and add the code to your HTML. Once your markup is ready, use Google’s Structured Data Testing Tool to validate it & add the generated code to your website's HTML.
Doing so can significantly improve your pages' representation in SERPs. It may even lead to rich results, dramatically increasing your click-through rates.
Lazy loading defers the loading of non-essential resources until they are needed. Optimizing lazy loading for Googlebot involves ensuring efficient rendering and indexing of these deferred elements.
Prioritize critical resources for initial loading, use the "loading" attribute, and employ JavaScript frameworks like Intersection Observer to trigger lazy loading for Googlebot.
Efficient lazy-loading enhances page speed, reduces server load, and positively influences Googlebot's ability to crawl and index content.
Canonicalization is the process of selecting the preferred URL when multiple URLs represent the same content. Proper canonicalization prevents duplicate content issues, consolidates link equity, and ensures Googlebot focuses on indexing the preferred version of your pages. Here are some best practices:
1. Rel="canonical" Tags: Use these tags to specify the preferred version of a page.
2. 301 Redirects: Implement 301 redirects for parameter handling and to indicate permanently moved pages.
3. Google Search Console: Set preferred URLs in Google Search Console to guide Googlebot.
4. Hreflang Annotations: Use hreflang annotations to manage international content and ensure the correct regional version of a page is indexed.
HTTP status codes are the server's response to a browser's request to view a page. Proper usage of HTTP status codes can prevent Googlebot from wasting its crawl budget on nonexistent or irrelevant pages and provide a better user experience. Key status codes to manage include:
1. 200 OK: Indicates successful page loads.
2. 301 Moved Permanently/302 Found: Indicates permanently or temporarily moved pages.
3. 404 Not Found/410 Gone: Indicates removed pages.
4. 500 Internal Server Error: Indicates server issues that need resolution.
Regularly check your site’s status codes and fix any unexpected errors to maintain efficient crawling and a positive user experience.
In conclusion, mastering Googlebot crawling is crucial for optimizing your website's SEO performance. Advanced tactics such as optimizing lazy loading, canonicalization, and managing HTTP status codes refine crawling efficiency. It ensures your website stands out in the crowded digital space. As Google continues to evolve its crawling algorithms, staying ahead with these sophisticated strategies ensures your website remains visible & competitive.
This is where Quattr can help you. Quattr can significantly enhance your website's crawling efficiency by offering advanced crawl analysis capabilities. Imagine discovering not just basic SEO issues but analyzing your site's performance against competitors with comprehensive weekly audits.
Quattr's tools render and analyze a broad set of pages, providing insights through historical trends on crawl errors, lighthouse audits, and site speed scores. This level of detail empowers you to make informed decisions, optimize your site to outrank competitors, and achieve superior SEO results.
Googlebot is the primary google web crawler used by Google to discover, crawl, and index web pages for its search engine results. It works by visiting websites, following links to find new content, and using a Chromium-based rendering engine to process pages exactly like a modern browser. This advanced approach allows the google crawler to understand both raw HTML and complex visual elements for accurate indexing.
The google crawler processes pages in two distinct stages: an initial HTML fetch followed by a comprehensive rendering phase. During the second stage, Googlebot executes JavaScript and builds the Document Object Model (DOM) to reveal content that wasn't in the initial source code. This ensures the google web crawler captures the full user experience, including interactive elements and visual layouts that rely on client-side scripts.
To verify a legitimate googlebot request, you must perform a reverse DNS lookup on the accessing IP address to ensure it originates from a Google server. A genuine google crawler will always resolve to a hostname ending in .googlebot.com or .google.com. This verification process is a critical part of a google crawler test to distinguish real bots from malicious actors who spoof user agents to scrape content.
The Google-InspectionTool is a specialized google crawler used specifically by diagnostic suites like Search Console's URL Inspection Tool and the Rich Results Test. Unlike standard automated crawling, this tool is triggered by user actions to perform a live google crawler test on a specific URL. It is essential for troubleshooting indexing discrepancies, as it provides real-time data on how Google's systems render and perceive your page.
You can request a recrawl by using the URL Inspection tool in Google Search Console to submit a specific page for a google crawler test. After entering the URL, click "Request Indexing" to signal the google web crawler to prioritize that page for a fresh visit. For large-scale site updates, resubmitting your XML sitemap is the most effective way to notify google crawlers of multiple content changes at once.

Quattr is an AI-native Search Visibility Platform founded in Palo Alto, California, built for mid-market and enterprise brands competing in the age of generative search. Recently recognized across G2’s Spring 2026 reports with #1 rankings in AEO Results, Usability, and Relationship, Quattr helps brands win visibility across traditional search and AI-generated answer surfaces.
Quattr’s AI agent, GIGA, evaluates content the way AI systems do, identifying gaps across structure, authority, internal linking, and discoverability to surface the highest-impact fixes. With capabilities like autonomous internal linking, E-E-A-T intelligence, and the new GIGA Landing Page Generator for keyword-matched, AI-search-ready pages, Quattr helps teams move from diagnosis to deployed changes without manual bottlenecks.



Try our growth engine for free with a test drive.
Our AI SEO platform will analyze your website and provide you with insights on the top opportunities for your site across content, experience, and discoverability metrics that are actionable and personalized to your brand.

.svg)
.svg)






